Download all the photos you've liked on Instagram
Adam Duke | 06 April 2013
Update
- I took what I learned from writing this script and wrapped it up in a web app that will keep track of your likes for you. Please email me if you have any feedback.
- In addition to using the 'users/self/media/liked/' endpoint shown below, any paged endpoint from the api can be used in the for the starting 'media_url'.
I recently discovered that Instagram will only ever return the last ~300 likes when trying to view the history of the things you've liked. I'm not sure if I'm the only one, but finding that out bothered me. I use the like feature to bookmark photos that I want to check out later, as well as letting someone know that I like their photo. I decided to build something that would help me keep track of my likes for the long term.
I broke my effort into a few parts:
- Learning how to work with the API
- Getting the correct data from Instagram
- Parsing the data
- Saving the photos
Learning how to work with the API
The Instagram API requires a client_id parameter in most cases, and an access_token parameter in cases where the request is on behalf of a user such as commenting or liking.
A quick check of the documentation at instagram.com shows that there is an API endpoint that will return a list of a signed-in user's likes. The documentation for that endpoint is here.
Instagram considers the list of a user's likes to be private, so it will require the additional access_token parameter. The first step is getting a client_id by registering a new application http://instagram.com/developer/clients/manage/. Once you have registered your application, you should see something similar to below. (Note that the application has been deleted so there's no worry about leaking secrets/tokens)
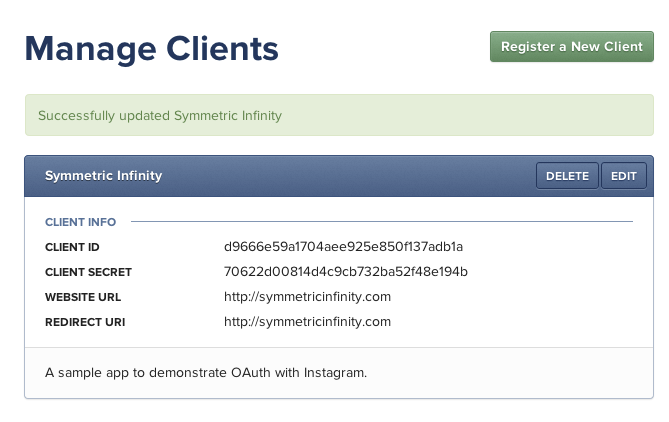
The second step is getting a valid access_token that can be used to make authenticated API calls.
The easiest way to get a valid access_token is to navigate to:
https://instagram.com/oauth/authorize/?client_id=CLIENT-ID&redirect_uri=REDIRECT-URI&response_type=tokenwhere CLIENT-ID is the client id you got when registering your new application, and REDIRECT-URI is the redirect uri that you provided when registering your new application. Navigating to that URL will yield a form where you can log into your Instagram account. Upon submitting the form, you will be redirected to the REDIRECT-URI and a valid access token will be given in the form of a URI fragment.
ex.

Getting the correct data from Instagram
Now we have everything we need to get data back from instagram. Let's create a ruby script so we can keep track of the steps we're running and make them repeatable. Create a file named ig_downloader.rb and we'll build from there.
One convenient way to make http requests in ruby is the RestClient library. Try adding the following to your ig_downloader.rb.
require 'restclient'
require 'json'
response = RestClient.get("https://api.instagram.com/v1/users/self/media/liked/?access_token=ACCESS_TOKEN")
json = JSON.parse(response)
pretty_json = JSON.pretty_generate(json)Parsing the data
This request above will return a json response. The response will have the "data" key, and its value is the array of likes that we are interested in. If we trim one of the likes down to the keys that will be useful for us, we're left with the following:
{
"images": {
"low_resolution": {
"url": "http://distilleryimage3.s3.amazonaws.com/874634609f1f11e2bf1822000aaa0492_6.jpg",
"width": 306,
"height": 306
},
"thumbnail": {
"url": "http://distilleryimage3.s3.amazonaws.com/874634609f1f11e2bf1822000aaa0492_5.jpg",
"width": 150,
"height": 150
},
"standard_resolution": {
"url": "http://distilleryimage3.s3.amazonaws.com/874634609f1f11e2bf1822000aaa0492_7.jpg",
"width": 612,
"height": 612
}
}
}Add the following to the script we started earlier to collect the standard resolution urls.
urls = json["data"].map do |item|
url = item["images"]["standard_resolution"]["url"]
endThe code above digs into each item and pulls out the images->standard_resolution->url property into an array. The urls variable should now be an array similar to:
http://distilleryimage3.s3.amazonaws.com/874634609f1f11e2bf1822000aaa0492_7.jpg
http://distilleryimage4.s3.amazonaws.com/278cd19e9efe11e2987422000a9e08f2_7.jpg
http://distilleryimage9.s3.amazonaws.com/c66aca849f0b11e2a46f22000a1de414_7.jpg
http://distilleryimage11.s3.amazonaws.com/db6be02c9ece11e2a97322000a1fb158_7.jpg
http://distilleryimage5.s3.amazonaws.com/14cddf2a9ca211e2a9d522000a1fb17d_7.jpg
http://distilleryimage7.s3.amazonaws.com/ab1666349bc411e2af9022000a1f9a23_7.jpg
http://distilleryimage5.s3.amazonaws.com/d24f34ec9bf611e29b2522000a9f13d5_7.jpg
http://distilleryimage8.s3.amazonaws.com/72ad419c9b3711e29a8222000a1f8ccf_7.jpg
http://distilleryimage7.s3.amazonaws.com/c000ac3298c011e2984f22000a1fb895_7.jpg
http://distilleryimage8.s3.amazonaws.com/f77edc84981a11e29d8c22000a1fbd8b_7.jpg
http://distilleryimage7.s3.amazonaws.com/9f514d1e976411e2aeca22000a9f18e5_7.jpg
http://distilleryimage0.s3.amazonaws.com/73260d1c968b11e29e7122000aaa0fd8_7.jpg
http://distilleryimage4.s3.amazonaws.com/4a3af692965e11e284c522000aa801df_7.jpg
http://distilleryimage5.s3.amazonaws.com/0908b17c965f11e2aea022000a9d0ee7_7.jpg
http://distilleryimage2.s3.amazonaws.com/c5900a44964511e2b68a22000a1f9af0_7.jpg
http://distilleryimage1.s3.amazonaws.com/c5a0d186957711e28e2c22000a1fb747_7.jpg
http://distilleryimage7.s3.amazonaws.com/87f72c68941911e2b1c522000a9f18eb_7.jpg
http://distilleryimage1.s3.amazonaws.com/1a75c70e944511e280cd22000a9f18de_7.jpg
http://distilleryimage9.s3.amazonaws.com/ba87806a93ce11e2ab0f22000a9f305a_7.jpg
Saving the photos
Now that we have all the urls, we can download each image and save it to a file. Add the following snippet to your script and try running it.
urls.each_with_index do |url, idx|
image = RestClient.get(url)
path = Dir.pwd + "/#{idx}.jpg"
File.open(path, 'w') {|f| f.write(image) }
endThe code above iterates each url and uses RestClient to download the image. It then creates a path that points to the current directory, and writes the image out to a file in the current directory.
At this point, the script should run and download the first page of images from Instagram's API. In order to download the rest of the pages we need to revisit the json data that comes back in the initial response.
In addition to the "data" key, there is a top level key named "pagination", which contains the information we need to get subsequent pages from the API.
Let's modify the script we started earlier to gather all the urls from all the available pages before downloading the images. We'll set an initial url and use a while loop to fetch it from the API, update the url, and fetch subsequent pages until there aren't any more. Note: I also added a short sleep during each call to the API because I experienced some http errors during development and slowing the request rate seemed to help.
The modified script should look like this:
require 'restclient'
require 'json'
media_url = "https://api.instagram.com/v1/users/self/media/liked/?access_token=ACCESS_TOKEN"
urls = []
while media_url != nil
response = RestClient.get(media_url)
json = JSON.parse(response)
media_url = json["pagination"]["next_url"]
json["data"].each do |item|
urls << item["images"]["standard_resolution"]["url"]
end
# don't slam instagram's api
sleep 0.2
end
urls.each_with_index do |url, idx|
image = RestClient.get(url)
path = Dir.pwd + "/#{idx}.jpg"
File.open(path, 'w') {|f| f.write(image) }
endThere are a number of other optimizations/modifications that can be added including not downloading images that we already have, saving the url for the image, etc… A more polished version of the script including some small extras can be found in this gist.
If you find any bugs or have any feedback at all feel free to send me an email.